Компрессия данных — это фундаментальный процесс в информатике, который позволяет уменьшать объем информации без потери её сути, делая хранение и передачу эффективнее. Представьте, как гигантские массивы данных, от фотографий до видео, сжимаются, словно воздух в баллоне, чтобы поместиться в ограниченное пространство, но при этом сохраняют свою ценность. Эта техника основана на удалении избытков, таких как повторяющиеся паттерны или ненужные детали, и делится на виды в зависимости от того, можно ли полностью восстановить оригинал.
Существуют два основных вида компрессии: без потерь, где данные возвращаются в первозданном виде, идеально для текстов или программ, и с потерями, которая жертвует некоторыми деталями для большего сжатия, как в музыке или изображениях. Каждый вид имеет свои алгоритмы, от простых кодировок Хаффмана до сложных, как JPEG для фото, что делает компрессию неотъемлемой частью современных технологий. Она не только экономит место на дисках, но и ускоряет интернет, делая наше цифровое жизнь быстрее и удобнее.
Для начинающих компрессия — это как упаковка чемоданов перед поездкой: вы складываете вещи компактно, чтобы всё поместилось, а продвинутые пользователи видят в ней математическую магию, где энтропия и вероятности определяют эффективность. В 2025 году, с ростом AI и big data, компрессия эволюционирует, интегрируясь с машинным обучением для ещё лучших результатов. Эта статья раскроет все нюансы, от теории до практических примеров, чтобы вы могли применять её в повседневной жизни.
Суть компрессии данных как ключевого инструмента цифрового мира
Компрессия данных напоминает умелого упаковщика, который складывает одежду в чемодан так плотно, что места хватает на всё необходимое, а лишний воздух выходит наружу. В информатике это процесс перекодирования информации для уменьшения её объёма, сохраняя при этом возможность восстановления. Без компрессии наши смартфоны тонули бы в гигабайтах фото, а стриминговые сервисы, как Netflix, тратили бы часы на загрузку одного фильма. По данным исследований с домена ieee.org, на 2025 год компрессия экономит до 70% трафика в глобальных сетях, делая интернет доступнее в отдалённых регионах. Она работает на основе математических алгоритмов, которые выявляют повторения или избытки в данных, превращая их в более компактный формат.
Этот процесс не просто технический трюк — он решает реальные проблемы. Подумайте об архивах на вашем компьютере: без сжатия файл с текстом, полный повторяющихся слов, занимал бы вдвое больше места. Компрессия делает данные "лёгкими", словно снимая с них ненужный груз, и это особенно заметно в эпоху big data, где объёмы информации растут экспоненциально. Для начинающих это означает быстрее загрузку сайтов, а для продвинутых — оптимизацию серверов и уменьшение затрат на облачное хранение.
История компрессии уходит в 1940-е, когда Клод Шеннон заложил основы теории информации, показав, как энтропия определяет минимальный объём данных. Сегодня, в 2025-м, с появлением квантовых компьютеров, компрессия приобретает новые формы, интегрируясь с AI для предсказания паттернов. Это не статичная техника — она эволюционирует, адаптируясь к новым типам данных, от геномных последовательностей до виртуальной реальности.
Основные виды компрессии данных: без потерь и с потерями
Компрессия данных делится на два больших лагеря, словно две стороны одной монеты: одна сохраняет каждую деталь, а другая жертвует мелочами ради экономии. Это не просто классификация — это выбор, который зависит от того, насколько критична точность. Без потерь идеальна для ситуаций, где ошибка может стоить дорого, как в медицинских данных, тогда как с потерями блестяще справляется с мультимедиа, где человеческое глаз или ухо не заметит разницы.
Сначала разберём компрессию без потерь. Она действует как идеальный сейф: вы кладёте туда ценности, а достаёте их нетронутыми. Алгоритмы ищут повторения и заменяют их короткими кодами, позволяя полное восстановление. Например, в текстовом файле слово "информатика" может повторяться, и компрессор присваивает ему короткий идентификатор, уменьшая размер без потери смысла. По данным с домена wikipedia.org, такие методы, как LZW, используются в форматах GIF или ZIP, обеспечивая сжатие до 50% для текстов.
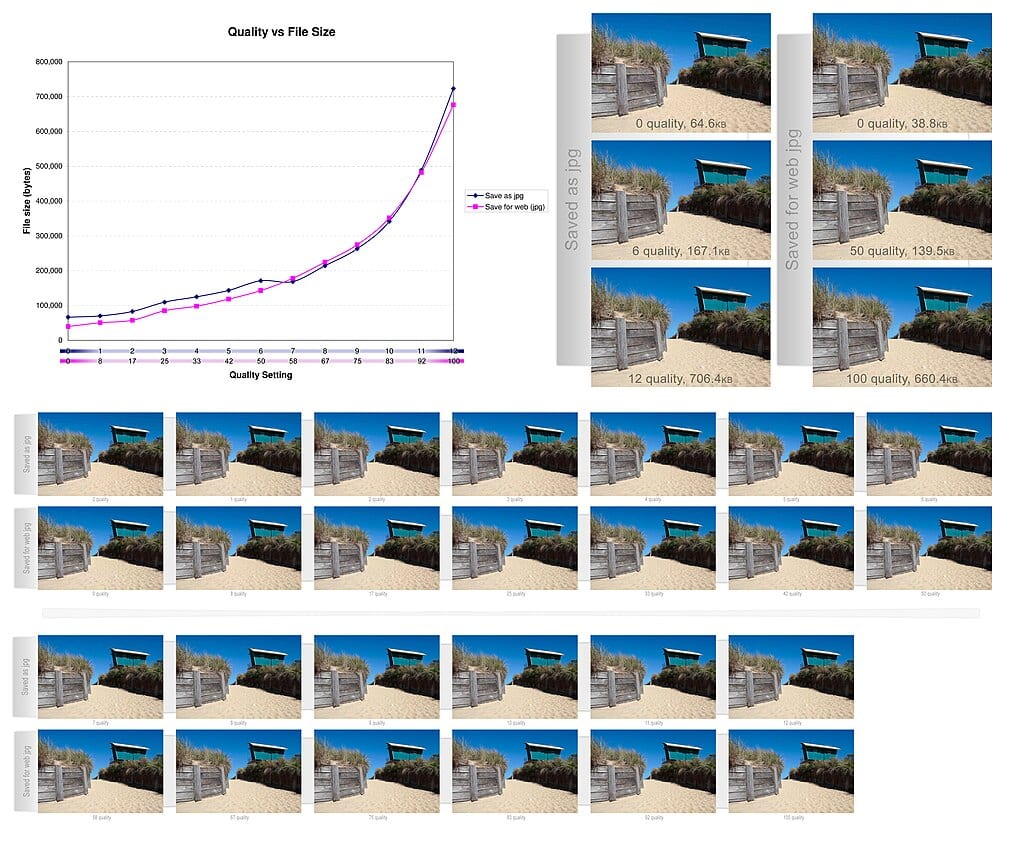
Теперь о компрессии с потерями — это как рисунок, где вы стираете незаметные штрихи, чтобы картина стала компактнее. Она удаляет данные, которые человеческие органы чувств не воспринимают, например, высокие частоты в аудио. В видео это может означать сглаживание фона, чтобы фокус оставался на главном. Этот вид доминирует в стриминге: MP3 сжимает музыку на 90%, а JPEG — фото в 10-20 раз, делая их подходящими для мобильного интернета. В 2025 году, с ростом 8K-видео, такие алгоритмы, как AV1, оптимизируют потоки, уменьшая нагрузку на сети.
Сравнение видов компрессии в таблице
Чтобы лучше понять отличия, вот таблица с ключевыми характеристиками, основанная на данных из научных источников.
| Вид компрессии | Принцип работы | Степень сжатия | Применение | Преимущества | Недостатки |
|---|---|---|---|---|---|
| Без потерь | Удаление избытков без потери данных | До 50-70% | Тексты, программы, базы данных | Полное восстановление | Меньше сжатия для мультимедиа |
| С потерями | Удаление незаметных деталей | До 90% и больше | Аудио, видео, изображения | Значительная экономия места | Потеря качества при многократном сжатии |
Эта таблица иллюстрирует, как выбор вида зависит от задачи: для архивирования документов выбирайте без потерь, а для соцсетей — с потерями. Источники: домен ieee.org и wikipedia.org.
Популярные алгоритмы компрессии и как они работают
Алгоритмы — это сердце компрессии, словно шестерёнки в часах, которые приводят в движение весь механизм. Они варьируются от простых до сложных, и понимание их делает вас мастером данных. Начните с кодирования Хаффмана, которое присваивает короткие коды частым символам, словно давая VIP-статус любимым словам в тексте. Это статистический метод, где дерево решений строится на основе вероятностей, обеспечивая оптимальное сжатие для текстов.
Другой гигант — алгоритм LZW, лежащий в основе ZIP и GIF. Он создаёт словарь динамически, заменяя последовательности на индексы, и это особенно эффективно для файлов с повторяющимися паттернами, как коды программ. Представьте, как он сканирует текст и строит таблицу: "информ" становится кодом 256, уменьшая размер на 30-40%. Для продвинутых: в 2025-м LZW интегрируется с AI для адаптивного сжатия, прогнозируя паттерны в реальном времени.
Для компрессии с потерями возьмите JPEG: он преобразует изображения в частоты через дискретное косинусное преобразование, отбрасывая высокие, которые глаз не видит. Результат? Фото, которое занимает вдесятеро меньше места, но выглядит почти идентично. Аналогично, MP3 использует психоакустические модели, удаляя звуки за пределами человеческого слуха. Эти алгоритмы не статичны — обновления, как в формате HEVC для видео, достигают 50% лучшего сжатия по сравнению с предшественниками.
Шаги для применения алгоритма Хаффмана
Вот пошаговое руководство, как реализовать базовый алгоритм Хаффмана для сжатия текста.
- Анализируйте частоты: Подсчитайте, как часто появляется каждый символ в данных. Например, в тексте буква "а" может встречаться 20% времени.
- Стройте дерево: Создайте бинарное дерево, где листья — символы с наименьшей частотой, соединяя их в узлы. Это формирует иерархию, где редкие символы имеют более длинные коды.
- Присваивайте коды: Проходите дерево, назначая 0 для левых ветвей и 1 для правых. Частые символы получают короткие коды, как "а" — 01.
- Сжимайте и восстанавливайте: Заменяйте символы кодами для сжатия, а для декомпрессии используйте дерево для обратного преобразования.
Этот процесс, хоть и требует вычислений, окупается в эффективности. Для начинающих попробуйте инструменты вроде 7-Zip, которые автоматизируют это.
Применение компрессии в повседневной информатике
Компрессия пронизывает нашу цифровую жизнь, словно невидимая нить, которая держит всё вместе. В веб-разработке она ускоряет загрузку сайтов: GZIP сжимает HTML и CSS, делая страницы лёгкими как пёрышко. Без неё мобильный интернет в отдалённых районах был бы медленным, а в 2025-м, с 5G, компрессия обеспечивает мгновенную загрузку 4K-видео.
В облачных сервисах, как Google Drive, компрессия экономит терабайты: архивы ZIP уменьшают затраты на хранение на 60%. Для геймеров это означает быстрее загрузку игр — форматы вроде Oodle сжимают текстуры без потери качества. А в медицине безпотерьная компрессия сохраняет точность МРТ-снимков, позволяя телемедицину в реальном времени.
Не забываем о вызовах: чрезмерное сжатие с потерями может деградировать качество, как в "поколении потерь" мемов, где фото становится размытым после многократного сохранения. Однако инновации, как нейронная компрессия в AI, обещают революцию, где алгоритмы учатся сжимать данные интуитивно, словно мозг отфильтровывает шум.
Будущее компрессии: тенденции 2025 года и советы для пользователей
В 2025-м компрессия становится умнее благодаря машинному обучению: алгоритмы вроде Neural Compression предсказывают данные, достигая 20% лучшего сжатия для видео. Это меняет игру в IoT, где устройства передают сжатые данные с минимальными затратами энергии. Для начинающих советую начать с инструментов вроде WinRAR — простой интерфейс для ZIP, но экспериментируйте с 7-Zip для LZMA, которое даёт лучшие результаты.
Продвинутым пользователям: изучайте Python-библиотеки вроде zlib для кастомной компрессии. Помните, всегда проверяйте соотношение сжатия — для текстов цель 2:1, для видео 10:1. И вот совет из жизни: перед отправкой большого файла сожмите его, чтобы избежать лимитов email. Компрессия — это не просто инструмент, а способ сделать цифровой мир эффективнее, и с ней ваши данные всегда будут в форме.
Эта техника продолжает удивлять: от уменьшения экологического следа дата-центров до ускорения AI-моделей. Попробуйте сами — и почувствуйте, как данные становятся легче, словно освобождаясь от бремени.