Компресія даних — це фундаментальний процес в інформатиці, який дозволяє зменшувати обсяг інформації без втрати її суті, роблячи зберігання та передачу ефективнішими. Уявіть, як гігантські масиви даних, від фотографій до відео, стискаються, ніби повітря в балоні, аби поміститися в обмежений простір, але при цьому зберігають свою цінність. Ця техніка базується на видаленні надлишків, таких як повторювані патерни чи непотрібні деталі, і поділяється на види залежно від того, чи можна повністю відновити оригінал.
Існують два основні види компресії: без втрат, де дані повертаються в первозданному вигляді, ідеально для текстів чи програм, і з втратами, яка жертвує деякими деталями для більшого стиснення, як у музиці чи зображеннях. Кожен вид має свої алгоритми, від простих кодувань Хаффмана до складних, як JPEG для фото, що робить компресію невід’ємною частиною сучасних технологій. Вона не тільки економить місце на дисках, але й прискорює інтернет, роблячи наше цифрове життя швидшим і зручнішим.
Для початківців компресія — це як пакування валіз перед поїздкою: ви складаєте речі компактно, аби все помістилося, а просунуті користувачі бачать у ній математичну магію, де ентропія та ймовірності визначають ефективність. У 2025 році, з ростом AI та big data, компресія еволюціонує, інтегруючись з машинним навчанням для ще кращих результатів. Ця стаття розкриє всі нюанси, від теорії до практичних прикладів, аби ви могли застосовувати її на щодень.
Суть компресії даних як ключового інструменту цифрового світу
Компресія даних нагадує вправного пакувальника, який складає одяг у валізу так щільно, що місця вистачає на все необхідне, а зайве повітря виходить назовні. У інформатиці це процес перекодування інформації для зменшення її обсягу, зберігаючи при цьому можливість відновлення. Без компресії наші смартфони тонули б у гігабайтах фото, а стримінгові сервіси, як Netflix, витрачали б години на завантаження одного фільму. За даними досліджень з домену ieee.org, станом на 2025 рік, компресія економить до 70% трафіку в глобальних мережах, роблячи інтернет доступнішим у віддалених регіонах. Вона працює на основі математичних алгоритмів, які виявляють повторення чи надлишки в даних, перетворюючи їх на компактніший формат.
Цей процес не просто технічний трюк — він вирішує реальні проблеми. Подумайте про архіви на вашому комп’ютері: без стиснення файл з текстом, повний повторюваних слів, займав би вдвічі більше місця. Компресія робить дані “легшими”, ніби знімаючи з них непотрібний вантаж, і це особливо відчутно в еру big data, де обсяги інформації зростають експоненційно. Для початківців це означає швидше завантаження сайтів, а для просунутих — оптимізацію серверів і зменшення витрат на хмарне зберігання.
Історія компресії сягає 1940-х, коли Клод Шеннон заклав основи теорії інформації, показавши, як ентропія визначає мінімальний обсяг даних. Сьогодні, у 2025-му, з появою квантових комп’ютерів, компресія набуває нових форм, інтегруючись з AI для передбачення патернів. Це не статична техніка — вона еволюціонує, адаптуючись до нових типів даних, від геномних послідовностей до віртуальної реальності.
Основні види компресії даних: без втрат і з втратами
Компресія даних поділяється на два великі табори, ніби дві сторони однієї монети: одна зберігає кожну деталь, а інша жертвує дрібницями заради економії. Це не просто класифікація — це вибір, який залежить від того, наскільки критична точність. Без втрат ідеальна для ситуацій, де помилка може коштувати дорого, як у медичних даних, тоді як з втратами блискуче справляється з мультимедіа, де людське око чи вухо не помітить різниці.
Спочатку розберемо компресію без втрат. Вона діє як ідеальний сейф: ви кладете туди коштовності, а дістаєте їх недоторканими. Алгоритми шукають повторення і замінюють їх короткими кодами, дозволяючи повне відновлення. Наприклад, у текстовому файлі слово “інформатика” може повторюватися, і компресор присвоює йому короткий ідентифікатор, зменшуючи розмір без втрати сенсу. За даними з домену wikipedia.org, такі методи, як LZW, використовуються в форматах GIF чи ZIP, забезпечуючи стиснення до 50% для текстів.
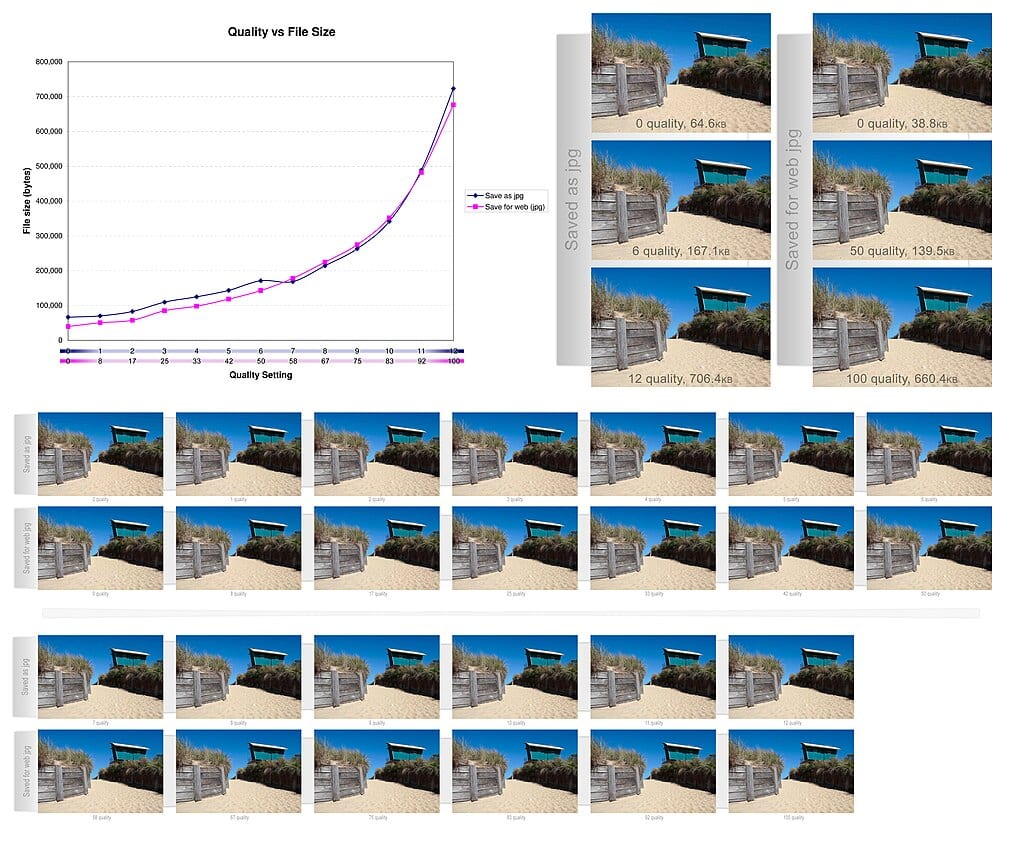
Тепер про компресію з втратами — це як малюнок, де ви стираєте непомітні штрихи, аби картина стала компактнішою. Вона видаляє дані, які людські органи чуття не сприймають, наприклад, високі частоти в аудіо. У відео це може означати згладжування фону, аби фокус лишався на головному. Цей вид домінує в стримінгу: MP3 стискає музику на 90%, а JPEG — фото на 10-20 разів, роблячи їх придатними для мобільного інтернету. У 2025 році, з ростом 8K-відео, такі алгоритми, як AV1, оптимізують потоки, зменшуючи навантаження на мережі.
Порівняння видів компресії в таблиці
Щоб краще зрозуміти відмінності, ось таблиця з ключовими характеристиками, базована на даних з наукових джерел.
| Вид компресії | Принцип роботи | Ступінь стиснення | Застосування | Переваги | Недоліки |
|---|---|---|---|---|---|
| Без втрат | Видалення надлишків без втрати даних | До 50-70% | Тексти, програми, бази даних | Повне відновлення | Менше стиснення для мультимедіа |
| З втратами | Видалення непомітних деталей | До 90% і більше | Аудіо, відео, зображення | Значна економія місця | Втрата якості при багаторазовому стисненні |
Ця таблиця ілюструє, як вибір виду залежить від завдання: для архівування документів обирайте без втрат, а для соцмереж — з втратами. Джерела: домен ieee.org та wikipedia.org.
Популярні алгоритми компресії та як вони працюють
Алгоритми — це серце компресії, ніби шестерні в годиннику, що приводять у рух весь механізм. Вони варіюються від простих до складних, і розуміння їх робить вас майстром даних. Почніть з кодування Хаффмана, яке присвоює короткі коди частим символам, ніби даючи VIP-статус улюбленим словам у тексті. Це статистичний метод, де дерево рішень будується на основі ймовірностей, забезпечуючи оптимальне стиснення для текстів.
Інший гігант — алгоритм LZW, що лежить в основі ZIP і GIF. Він створює словник динамічно, замінюючи послідовності на індекси, і це особливо ефективно для файлів з повторюваними патернами, як коди програм. Уявіть, як він сканує текст і будує таблицю: “інформ” стає кодом 256, зменшуючи розмір на 30-40%. Для просунутих: у 2025-му LZW інтегрується з AI для адаптивного стиснення, прогнозуючи патерни в реальному часі.
Для компресії з втратами візьміть JPEG: він перетворює зображення на частоти через дискретне косинусне перетворення, відкидаючи високі, які око не бачить. Результат? Фото, що займає вдесятеро менше місця, але виглядає майже ідентично. Аналогічно, MP3 використовує психоакустичні моделі, видаляючи звуки за межами людського слуху. Ці алгоритми не статичні — оновлення, як у форматі HEVC для відео, досягають 50% кращого стиснення порівняно з попередниками.
Кроки для застосування алгоритму Хаффмана
Ось покроковий посібник, як реалізувати базовий алгоритм Хаффмана для стиснення тексту.
- Аналізуйте частоти: Підрахуйте, як часто з’являється кожен символ у даних. Наприклад, у тексті літера “а” може зустрічатися 20% часу.
- Будуйте дерево: Створіть бінарне дерево, де листки — символи з найменшою частотою, з’єднуючи їх у вузли. Це формує ієрархію, де рідкісні символи мають довші коди.
- Присвоюйте коди: Проходьте дерево, призначаючи 0 для лівих гілок і 1 для правих. Часті символи отримують короткі коди, як “а” — 01.
- Стискайте та відновлюйте: Замініть символи кодами для стиснення, а для декомпресії використовуйте дерево для зворотного перетворення.
Цей процес, хоч і вимагає обчислень, окупається в ефективності. Для початківців спробуйте інструменти як 7-Zip, які автоматизують це.
Застосування компресії в повсякденній інформатиці
Компресія пронизує наше цифрове життя, ніби невидима нитка, що тримає все разом. У веб-розробці вона прискорює завантаження сайтів: GZIP стискає HTML і CSS, роблячи сторінки легкими як пір’їнка. Без неї мобільний інтернет у віддалених районах був би повільним, а в 2025-му, з 5G, компресія забезпечує миттєве завантаження 4K-відео.
У хмарних сервісах, як Google Drive, компресія економить терабайти: архіви ZIP зменшують витрати на зберігання на 60%. Для геймерів це означає швидше завантаження ігор — формати як Oodle стискають текстури без втрати якості. А в медицині безвтратна компресія зберігає точність МРТ-знімків, дозволяючи телемедицину в реальному часі.
Не забуваймо про виклики: надмірне стиснення з втратами може деградувати якість, як у “поколінні втрат” мемів, де фото стає розмитим після багаторазового збереження. Проте інновації, як нейронна компресія в AI, обіцяють революцію, де алгоритми вчаться стискати дані інтуїтивно, ніби мозок відфільтровує шум.
Майбутнє компресії: тенденції 2025 року та поради для користувачів
У 2025-му компресія стає розумнішою завдяки машинному навчанню: алгоритми як Neural Compression передбачають дані, досягаючи 20% кращого стиснення для відео. Це змінює гру в IoT, де пристрої передають стиснуті дані з мінімальними витратами енергії. Для початківців раджу почати з інструментів як WinRAR — простий інтерфейс для ZIP, але експериментуйте з 7-Zip для LZMA, яке дає кращі результати.
Просунутим користувачам: вивчайте Python-бібліотеки як zlib для кастомної компресії. Пам’ятайте, завжди перевіряйте співвідношення стиснення — для текстів мета 2:1, для відео 10:1. І ось порада з життя: перед відправкою великого файлу стисніть його, аби уникнути лімітів email. Компресія — це не просто інструмент, а спосіб зробити цифровий світ ефективнішим, і з нею ваші дані завжди будуть у формі.
Ця техніка продовжує дивувати: від зменшення екологічного сліду дата-центрів до прискорення AI-моделей. Спробуйте самі — і відчуйте, як дані стають легшими, ніби звільняючись від тягаря.